

상세 컨텐츠
본문
* 본 칼럼은 『한국음악지각인지학회 2023 제2회 여름학교』와 『제67차 한국음악지각인지학회』의 강연을 기반으로 작성하였음을 밝힙니다.

2023년 ChatGPT 열풍이 불면서 생성형 인공지능에 대한 대중들의 관심이 급격하게 증가했다. 이러한 관심은 텍스트를 높은 성능으로 생성해낼 수 있는 거대 언어 모델(LLM, Large language model)뿐만 아니라, 그림, 동영상 등 다양한 형태의 데이터를 제작할 수 있는 인공지능에 관한 관심으로 확대되었다.
음악도 예외는 아니다. 유튜브에 ‘AI 커버’를 검색하면 어렵지 않게 인공지능이 생성한 오디오를 들어볼 수 있다. 인공지능이 가수 ‘딘’의 목소리로 아이돌 그룹 뉴진스의 ‘New Jeans’ 노래 커버를 생성한 영상은 2024년 3월 기준 360만 회의 조회수를 기록했다. 인공지능을 활용한 음악이 기술로서만이 아니라, 새로운 대중 예술 장르로서 높은 가치를 지닌다는 것을 보여준 사례이다.
이렇듯 조금은 멀어 보일 수 있는 두 분야, 음악과 과학은 함께 맞물리며 새로운 분야와 문화를 형성하고 있다. 과학이 말하는 음악이란 무엇이며, 음악과 과학 사이에는 어떤 교집합이 있는지, 나아가 현대의 음악 과학 기술은 어디를 향하고 있는지 알아보자.
귀가 감지하는 신호, 소리

소리는 음파라는 파동의 일종이다. 파동이란, 평형 상태로부터 진동이나 변화가 공간상에서 전달되는 현상을 일컫는다. 음파는 공기를 매질로 하여 전파되는 파동이다. 물체가 진동하면서 주변의 공기를 움직이면 그 진동이 공간으로 퍼져 나간다. 소리가 전달되는 과정을 그래프로 표현하면 시간에 따른 공기의 압력으로 그릴 수 있다. 압력이 낮은 부분과 높은 부분이 주기적으로 나타나며 시간과 공간에 따라 변화하는 형태를 가진다.
귀는 음파를 감지하는 감각 기관이다. 외부 공기의 진동이 고막을 진동시키면 이소골과 같은 뼈에 진동이 전달된다. 이 진동은 달팽이관의 청세포를 통해 전기신호로 변환되고, 뇌에서 소리로 인지된다. 달팽이관의 구조 때문에 사람의 귀는 고주파 성분보다 저주파 성분에 민감하다. 저주파수를 감지하는 부분이 고주파수 대역을 감지하는 부분보다 비교적 민감하기 때문이다.

사람은 두 귀를 통해 소리를 공간적으로 감지할 수 있다. 하나의 근원(source)으로부터 생성된 음파여도 각 귀에 들리는 소리의 크기와 도착 시각이 다르다. 소리가 나는 곳부터 두 귀까지의 거리가 다르기 때문에 도착 시각 차이가 발생하며, 한쪽 귀에 들어오는 소리의 고주파수 성분이 사람 머리에 의해 일부 감쇠하는 두영 현상(head shadow effect)으로 인해 소리의 크기가 감소한다. 두 귀에 들리는 음의 시간 차이를 ITD(Interaural Time Difference)라 하고, 크기 차이를 ILD(Interaural Level Difference)라 하며, 뇌는 ITD와 ILD를 기반으로 소리의 근원을 추정한다.
신호처리, 표현의 정보를 해석하다
음악과 기술의 접목에는 신호 처리 분야의 지식이 필요하다. 신호란 정보를 표현하는 변화의 패턴이라고 할 수 있다. 특히 음파는 시간에 대해 정보가 변화하는 시계열 신호(time series signal)이다.
소리뿐만 아니라 이미지도 신호가 될 수 있다. ‘시간’에 따라 변화를 보이는 소리와 비슷하게, 이미지는 ‘공간’에 따라 변화를 보이는 신호이기 때문이다. 모든 주기적인 파형 신호는 삼각 함수인 사인(sin)과 코사인(cos)의 합으로 표현될 수 있다. 다른 말로 하면 원 위에서 움직이는 한 점에 관한 그래프의 합으로 표현할 수 있다는 의미이다. 아래 자료는 신호의 일종인 ‘이미지’를 사인과 코사인의 조합으로 시각화한 것이다.
복잡한 신호에서 유의미한 정보를 뽑아내기 위해 사용되는 방법 중 하나가 ‘푸리에 변환(Fourier transform)’이다. 푸리에 변환은 각 주파수 성분을 담은 푸리에 행렬의 행(row) 하나가 원본 신호와 얼마나 닮았는지 내적을 통해 추출한다. 결과적으로 원본 신호 속 특정 주파수의 함량을 알 수 있으며, 복잡했던 파형을 단순한 사인 및 코사인 파형의 합으로 분해하여 분석할 수 있다.

푸리에 변환을 거치면 시간 영역(Time Domain)이었던 신호가 주파수 영역(Frequency Domain)이 된다. 음파에 변환을 적용하여 분석하면, 소리가 어떤 음으로 이루어져 있는지 확인할 수 있다.

푸리에 변환은 음악 작곡 과정에서도 흔히 볼 수 있다. 디지털 신호처리의 원리를 이용하여 오디오를 생성하거나 편집하는 프로그램을 디지털 오디오 스테이션(Digital Audio Workstation, DAW)이라 한다. 에이블톤(Ableton), 큐베이스(Cubase)와 같은 DAW는 위 사진과 같이 푸리에 변환된 소리의 그래프를 제공한다. DAW에서 가능한 오디오 처리 중 이퀄라이제이션(Equalization, EQ)은 특정 주파수 범위의 볼륨을 조절하는 기본적인 기능이다. 작곡에서 EQ를 사용하면 녹음된 소리나 가상악기의 음색을 바꿀 수 있다. 특정 주파수 영역대만 높이거나 낮추어 새로운 느낌의 소리를 만들어낼 수 있다는 의미이다. 사용자는 각 주파수 영역의 신호 크기를 보면서 원하는 음색이 되도록 조정할 수 있고, 소리를 디자인할 수 있다.
인공지능이 듣는 소리의 형태
인공지능은 어떻게 사람처럼 ‘들을’ 수 있을까? 학자들은 사람 귀의 특성을 모방한 데이터에 대해 연구했고, 그러한 데이터를 만들기 위해 등장한 것이 멜 스케일(Mel-scale)과 멜 필터 뱅크(Mel Filter Bank)이다.
멜 스케일이란, 듣는 사람이 동일한 차이라고 느끼는 지각적 음계이다. 앞서 언급했던 것처럼, 달팽이관은 저주파수 영역대의 소리를 고주파수 영역대보다 더 민감하게 받아들인다. 즉 멜 스케일은 주파수별로 감지가 달라지는 귀의 특성을 모방한 척도라 할 수 있다.
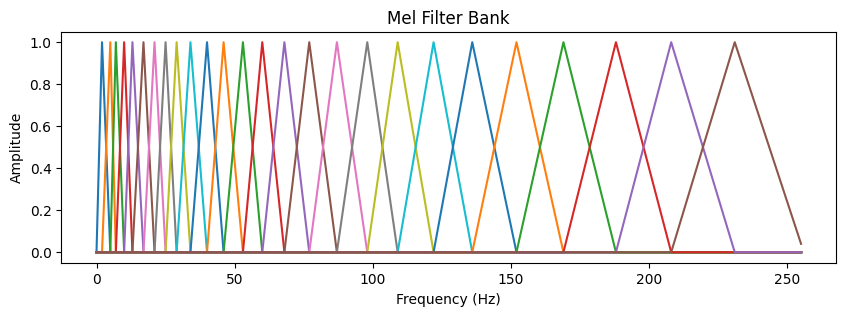
멜 스케일을 오디오 데이터에 적용하기 위하여 필터 형태로 만들면 멜 필터 뱅크를 얻을 수 있다. 주파수가 작을수록 필터가 더 촘촘하다.
실제 음악 연구에서는 멜 필터 뱅크를 적용한 피처(Feature)인 멜 주파수 셉스트럴 계수(Mel-frequency Cepstral Coefficient, MFCC)를 주로 사용한다. MFCC는 사람 귀의 특성을 수학적으로 반영하고, 데이터의 크기를 효과적으로 단축하기 때문에 음악 관련 인공지능을 학습시킬 때 이용된다.

MFCC 피처를 형성하는 과정은 먼저, 원본 오디오 신호에 표본추출(sampling)과 윈도윙(windowing)을 한다. 오디오 데이터를 잘게 자르는 과정으로, 연속성을 보존하기 위해 신호를 50% 정도 겹치도록 아주 작은 시간단위(20~40ms)로 분할한다. 이후 고속 푸리에 변환(FFT, Fast Fourier Transform)을 통해 스펙트럼(spectrum)을 생성한다. 여기서 고속 푸리에 변환은 이산 푸리에 변환(DFT, Discrete Fourier Transform)을 더 효율적으로 연산하는 알고리즘이며, 기계가 연산하는 데이터는 완벽하게 연속적일 수 없기 때문에 이산 신호로 연산한다. 다음으로 사람 귀의 특성을 반영하기 위하여 멜 필터 뱅크를 적용시키고 고속 푸리에 역변환(IFFT, Inverse Fast Fourier Transform)과 로그를 취하는 셉스트럴 분석(cepstral analysis) 과정을 수행하면 마침내 MFCC 피처가 추출된다. 형성된 데이터의 가로축은 시간(time), 세로축은 MFCC이다.
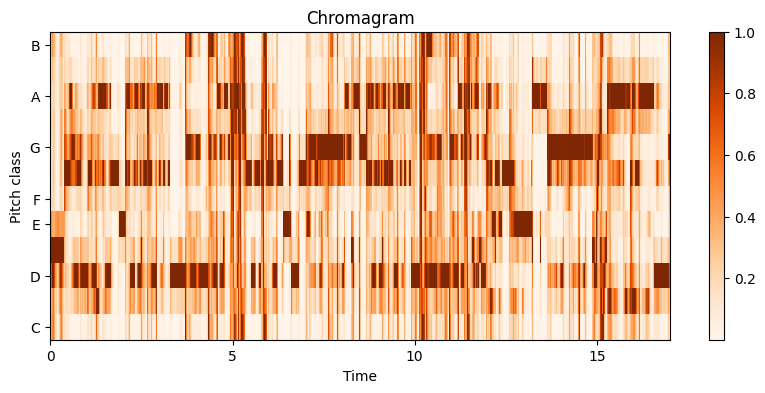
MFCC 이외에도 인공지능의 응용 분야나 활용에 따라 크로마그램(chromagram) 등의 피처가 사용된다. 크로마그램은 ‘도레미파솔라시도(CDEFGABC)’로도 알고 있는 12개 음계의 서로 다른 피치(pitch)와 관련이 있다. 1옥타브 도, 2옥타브 도와 같이, n옥타브 차이가 나는 주파수 성분들을 피치별로 모두 합산하여 특정 시간에 하나의 피치 집단(pitch class)로 표현하는 방식이다.
음악과 과학, 그 교집합이 만드는 공간
지난 해 12월 21일, Y사는 도쿄에서 특별한 프로젝트를 공연으로 선보였다. Y사는 ‘피아노를 잘 치고 싶다’는 장애를 가진 소녀의 소망을 위해 AI 자동 반주 피아노(AI-assisted Auto-accompanied Piano) 개발했다. 이 피아노는 인공지능 기술을 이용하여 장애, 음악 실력, 연령과 관계없이 손가락 하나만으로도 연주할 수 있다. 소녀는 인공지능 기술이 탑재된 피아노로 오케스트라 및 합창단과 함께 합주할 수 있었다.
음악의 매력은 함께하는 것에 있다. 동일한 박자 위에서 하나의 소리를 만들기 위해 함께하는 것, 노래와 가사를 통해 서로의 감정을 함께하는 것. 인공지능 기술이 극도로 발전하면서 음악가를 포함한 많은 사람이 두려움을 느끼는 것 같다. 인공지능이 인간만의 영역이라고 여겼던 예술 분야를 침범해서일까? 새로운 기술이 가져올 미래가 불투명해서일까? 실제로 과학은 누군가의 하루를 위협하기도 한다. 하지만 과학 기술 덕분에 함께할 수 있었던 자동 반주 피아노 프로젝트처럼, 때로는 소중한 가치를 실현할 수 있는 내일을 열어준다. 어떤 미래를 맞이할 것인가? 인간만이 할 수 있다고 생각했던 행위의 진정한 의미를 고민할 때 우리가 곧 맞이할 미래의 형태를 가늠할 수 있을 것이다.
DGIST 기초학부 이하임 학생 haim1121@dgist.ac.kr
'학술' 카테고리의 다른 글
| [2024 노벨 화학상] 인공지능을 이용한 단백질 구조 예측 (0) | 2024.11.19 |
|---|---|
| [2023 UGRP 우수연구] 상대 쥐의 경험에 따른 social buffering 차이 (0) | 2024.09.02 |
| 냉각 속도 바꿔봐도 초전도체 아니야… DGIST 연구진의 LK-99 합성 결과 (0) | 2024.05.06 |
| [칼럼] 양자역학을 해석하길 포기하지 말아야 하는 이유 – 관계론적 해석 (0) | 2024.03.18 |
| 양자역학으로 생명 현상의 기묘함을 들추다 – 양자생물학 (1) | 2023.11.28 |



댓글 영역